题目是一句golang编程箴言,对它的理解可大可小。
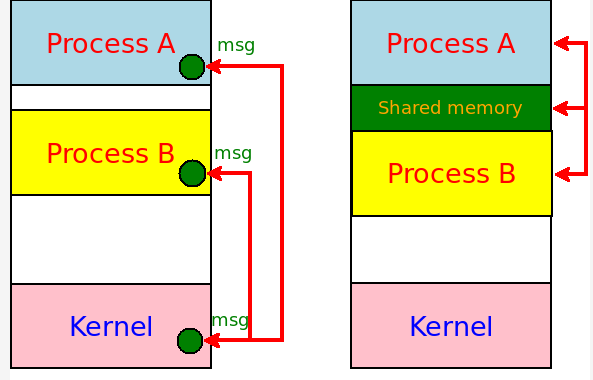
往小了说,golang建议使用channel来共享信息而不是使用共享内存,这是一种优雅的方式,避免了数据同步带来的繁琐和低效。
往大了说,本质上还是让资源去调度请求,而不是让请求去调度资源。
有些时候,思维的转变,问题的视角,会带来意想不到的收获
资源就那么多,所有请求有序使用资源的方式就是通信的方式,反过来,为每个请求虚拟出它独占资源的假象,那就是共享的方式。两种截然不同的方式,差异体现在仲裁成本,这个成本决定了它们承载并发的能力。
一个一个说。
电路交换 vs 分组交换
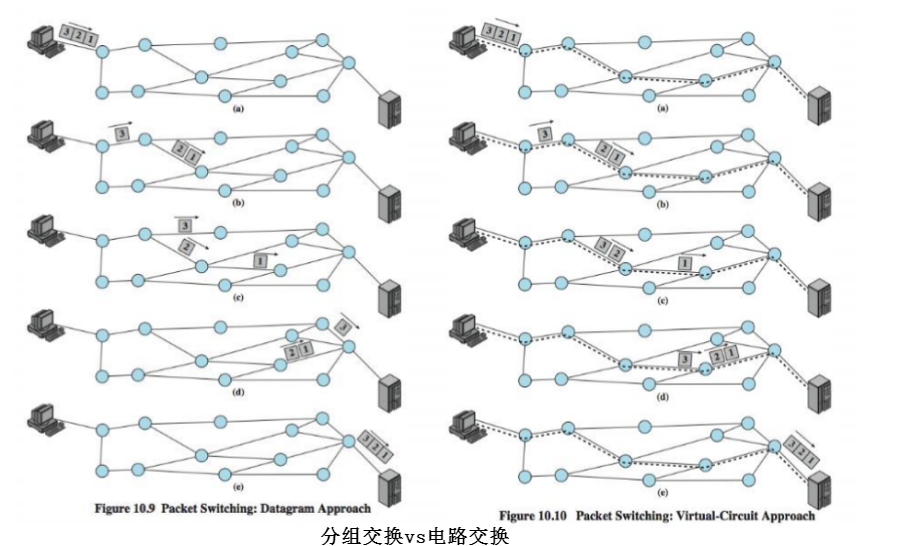
- 电路交换试图占有整条电路(其实是最后一公里),若不成功,必须等到成功。
- 分组交换将长信息分割成若干小数据包,小数据包统计复用链路。
批处理系统 vs 分时系统
- 批处理用户一旦使用系统,则会独占系统到任务完成,其它用户等待。
- 分时系统将时间分片,多用户被调度复用时间片。
CSMA/CD vs 交换式以太网
- CSMA/CD主机试图独占总线发送数据包,若不成功便退避直到成功。
- 交换式以太网数据包在交换机有序排队,复用buffer。
Apache vs Nginx
- Apache为每一个请求生成一个task,该task一旦获得CPU,其它task将等待。
- Nginx采用异步模型,所有请求分时复用固定数量task的CPU时间。
共享内存 vs erlang/go channel
- 共享内存对写写以及读写是互斥,每次只允许一个操作,其它不得不等待,重试。
- erlang/go channel将内容拆解为事务消息,依靠消息的有序传递共享信息。
…
我们来看上述两两比较的共性。
可将上述所有的二者抽象为争抢模式和有序模式:
- 对于争抢模式,本质上需要对冲突进行仲裁。
- 对于有序模式,本质上需要对并发进行调度。
所谓对冲突进行仲裁,意思就是发生冲突后怎么办。无论是退避重试,还是等待,此期间均是什么都做不了,且仲裁本身需要昂贵的成本。
并发调度就会好太多,有序化便无冲突,也就没有仲裁成本了,没有了仲裁,也就无需重试,等待,便可以干别的了,处理完全异步化。
我们再来对比之前技术优劣:
电路交换 vs 分组交换
- 电路交换一旦占线,你需要自己不断重试。
- 分组交换你只管发数据包,交换节点会自动调度这些数据包到达目的地后重组。
批处理系统 vs 分时系统
- 批处理系统一旦系统被占,你就要排队等待或者待会儿再来。
- 分时系统你只需要下发任务,任务调度系统会让所有用户的任务分时复用时间片。
CSMA/CD vs 交换式以太网
- CSMA/CD网卡需要不断监听冲突并重试。
- 交换式以太网卡只需要发包,交换机会排队调度来不及转发的数据包。
Apache vs Nginx
- Apache线程/进程若没被调度到CPU,就需要等待直到被调度切换至CPU。
- Nginx只需将事件通知到,工作进程便会轮询处理完所有请求。
共享内存 vs erlang/go channel
- 共享内存访问需要加锁,若持锁失败,要么忙等重试,要么待会儿再来。
- erlang/go channel以消息传递通信,消息发出后就不用管了,除非它希望得到回馈,完全异步。
可见,这又是一个殊途同归。同类的还有:
- PCI vs PCIe,从总线到交换。
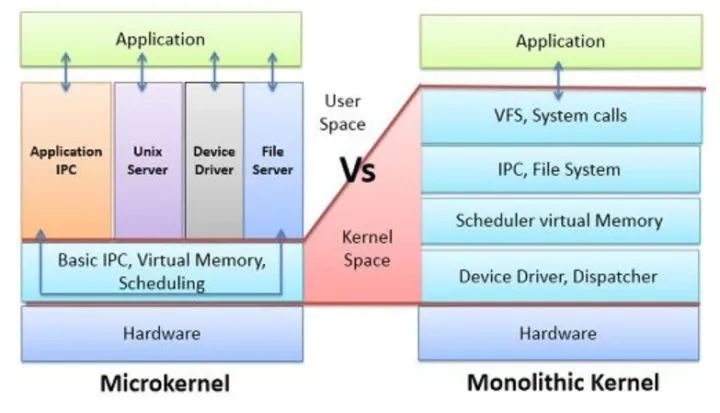
- 宏内核 vs 微内核,从共享数据结构到消息传递。
- Spin/RW Lock vs RCU Lock,从争抢锁到操作副本原子更新。
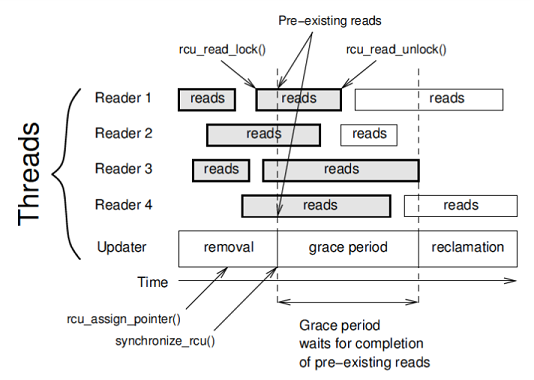
RCU原理
为什么冲突仲裁的争抢模式无法承载大并发,因为过载的冲突仲裁开销会将资源淹没,若要承载大并发,必然要采用调度的方式。要理解这一要素,需要换一个视角。
我们看操作的是信息的本身,还是信息的副本。
回到本文题目,“以通信方式共享内存”操作信息的副本, 而“以共享内存方式通信”则操作信息本身。
操作信息副本可以保证同时有且只有一个实体操作该副本,如果有两个实体需要操作该副本,那就再复制一个副本,这就保证了无冲突,业务流是可控无阻塞的。
RCU可做到业务无阻塞并发,无论是spinlock还是rwlock,都做不到。spinlock/rwlock锁临界区,造成临界区串行化,而RCU没临界区,它将本属于临界区的逻辑作为副本操作,择机原子更新,这便可做到无阻塞并发。
操作副本是无阻塞并发的甘泉,如果把并发看作是时间扩展性,那么将信息共享到远方则是空间扩展性,完成这件事的是网络,目前它是TCP/IP网络。TCP/IP网络采用了“以通信方式共享内存”的方式,它无疑是正确的。
我不懂erlang,但大致知道它的意思,erlang没有变量,只操作副本,它是通信网络在编程语言上的映射,对于golang,大概也是如此,使用go channel可以像网络收发一样来处理信息。
我们看socket接口,它实属用通信的方式共享内存的古老方式。
socket接口一开始是进程间通信机制,与之通信的进程可在本机,也可在远处,可在世界任意地方。“以通信方式共享内存“,是最原始的编程模式,一直到现在依然正确。
共享内存是一种本地优化,仅有编程意义,却没有扩展性,无论是无阻塞并发的时间扩展性,还是将信息传递给远方的空间扩展性。
共享内存是一种本地优化,优化的是指令操作延时,与其将信息封装成消息并传递,不如直接操作信息本身,它编程更简单,代码指令更少,执行延时更低。但高并发并不care指令延时,高并发care同时执行的有效指令数,而spin,switch不属于有效指令,故共享内存天生不与高并发配对。
此外,还是那个观点,网络编程场景,普遍毫秒级的单流通信延时,共享内存相比消息传递节省个微妙甚至纳秒级的操作延时,并无太大意义。要怪就怪光速吧。
从云原生开始
云原生是面向微服务的架构,而消息传递是微服务交互的媒介,每个工人都接触过关于消息队列的概念,正是消息支撑了云原生微服务。
消息并不封装状态,消息本身无状态,状态通过消息之间的交互来体现。消息交互可自由组合,这是分布式的源泉,而云原生本身就是面向分布式的设计。
一个部署云原生应用的IDC机房就是缩小版的全球TCP/IP互联网,无状态的消息在分布式的微服务之间传递,状态仅由微服务的交互定义和维护。
甚至一台物理主机内部板卡也成了微型版的全球TCP/IP互联网,无状态的消息在分布式的模块之间传递,状态仅由模块之间的交互定义和维护。
共享内存类似总线,大家拥有平等访问权,但写访问时要独占。我们可以从总线和消息交换的关系看共享内存的处境。
曾经,主机主板上很多总线,很多模块都要先争抢获得总线控制权才能与CPU或别的模块通信,但后来PCIe将总线改成了由Hub互联的交换网络,采用消息交换替换了总线仲裁。
以太网在此之前已经走过了同样的轨迹。
近来年被工人们提倡的微内核思想,大致也是这么回事,将对共享数据结构的操作换成了消息传递。
为什么这些都和全球TCP/IP互联网类比呢?因为TCP/IP的基础就是异步的,无状态的,分布式的,消息传递的分组交换网。
总线简单朴素,随着系统规模的扩大,总线争抢带来的时间损耗指数级上升,人们发现总线无法支持高并发及无法物理扩展时,消息传递便替换了总线。大规模系统,消息操作带来的额外延时是可以忽略不计的。
无论内部板卡,局域网,PCI,操作系统都是从局域范围开始的,它们一开始从总线开始便不足为奇。然而互联网一开始就是连接分布式广域端的,一开始就不适合采用总线结构,这反过来说明总线在分布式场景的不适用。
我一向赞美TCP/IP端到端原则,正是它无状态的IP细腰让互联网规模得以任意扩大而不引入额外开销,而细腰也是无状态消息交换的核心,只在发送端和接收端之间定义和维护状态,而不是所有端一起维护共享总线或内存的状态。
因此,消息传递也遵循端到端原则,可以自由扩展规模,总线和共享内存则相反。
以上从局域扩而大之的视角,我们看到了消息传递替换总线的趋势。
反过来,从广域向内缩,规模在渐小,传输延时在渐短,越来越不分布式,无状态消息传递带来的可扩展优势越发无用武之地,其额外封装带来的额外延时逐渐承担了端到端延时的大头。
除去额外的消息封装和传输操作,所有不多的实体直接操作信息所在的内存,最小化端到端延时便成了可观的收益,因此,总线和共享内存便是微缩版系统的极致了。
总结
这就两边都说得通了,从小规模到大规模,总线和共享内存被消息传递替代,从大规模到小规模,总线和共享内存则是消息传递的优化。
就像广义相对论,牛顿力学,量子力学一样,不同的规模尺度有不同的哲学。
参考资料:https://mp.weixin.qq.com/s/AGJcryYmWyNHgmb_d1jFBA