我现在有一套日志记录系统,底层存储使用的是elasticsearch。记录的数据为接口请求日志,一般是一次请求一个日志。
大概记录的关键的字段有请求的接口名,方法名,请求耗时。
我现在想统计出,所有接口的按照分钟统计的峰值速率情况。
Kibana配置方式
我们可以进入kibana,然后进到dashboard,创建新的dashboard,然后选择 Create visualization,我们选择table类型。
我选择好自己的数据索引,然后可以添加一些自己需要的过滤条件,比如我只统计服务端的接口日志和生成环境的日志:

我增加这样的过滤
然后在右侧的Metrics我们配置Metrics:
数据Metrics
Aggregation我们选择:Max Bucket
然后我们配置这个Max Bucket:我们选择 Aggregation:Date Histogram,Field我们选择:@timestamp (我们数据上有个日期字段就是这个)。 然后我们点击下面的高级(Advanced),我们在json input里面填入:
{
"fixed_interval":"1m"
}这个目的是配置咱们统计口径是按照分钟来的,我们统计的是每分钟的请求峰值。
数据Buckets
按接口过滤:
我们点击下面的Buckets里面的Add,我们选择Split rows,我们Aggregation选择Terms,然后Field我们选择我们的接口字段。
我们还需要按照方法来过滤,重复上面操作,我们再增加个接口字段的Terms的Aggregation的Split rows。
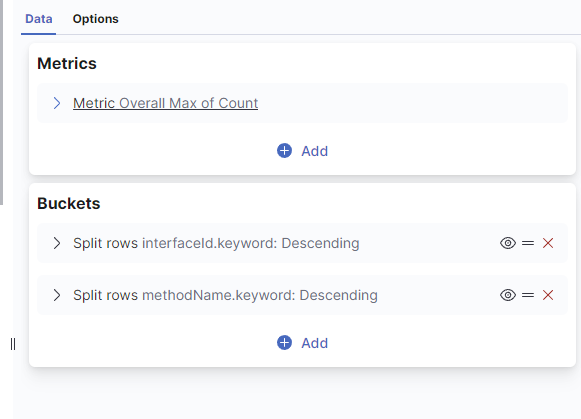
然后我们点击下面的update,左侧表格就能看到我们要的数据了。
我们点开下面的网络请求,可以看到咱们配置出来的请求参数:
post请求到 :kibana_url/internal/bsearch
参数是:
{
"batch": [
{
"request": {
"id": "Fk9mUk04SERXU2tHWXNzZmgyNXVieUEhb0hhd2JIb0ZRaXV0MHhHMVBDTHJBUTo0NTc4MTIzNjky",
"params": {
"index": "log-jsf-*",
"body": {
"aggs": {
"2": {
"terms": {
"field": "interfaceId.keyword",
"order": {
"_key": "desc"
},
"size": 20
},
"aggs": {
"3": {
"terms": {
"field": "methodName.keyword",
"order": {
"_key": "desc"
},
"size": 20
},
"aggs": {
"1": {
"max_bucket": {
"buckets_path": "1-bucket>_count"
}
},
"1-bucket": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1m",
"time_zone": "Asia/Shanghai",
"min_doc_count": 1
}
}
}
}
}
}
},
"size": 0,
"fields": [
{
"field": "@timestamp",
"format": "date_time"
}
],
"script_fields": {},
"stored_fields": [
"*"
],
"runtime_mappings": {},
"_source": {
"excludes": []
},
"query": {
"bool": {
"must": [],
"filter": [
{
"match_phrase": {
"providerSide": true
}
},
{
"match_phrase": {
"env.keyword": "production"
}
},
{
"range": {
"@timestamp": {
"format": "strict_date_optional_time",
"gte": "2024-05-04T09:00:00.000Z",
"lte": "2024-05-05T09:22:04.550Z"
}
}
}
],
"should": [],
"must_not": []
}
}
},
"preference": 1714872221324
}
},
"options": {
"sessionId": "d2c5e9fc-f319-4df6-b104-933b6723776b",
"isRestore": false,
"strategy": "ese",
"isStored": false,
"executionContext": {
"type": "visualization",
"name": "Data table",
"id": "",
"description": "接口峰值调用",
"url": ""
}
}
}
]
}转换成Elasticsearch请求
我们的日志index为:http-request-log-*
请求地址:elasticsearch:9200/http-request-log-*/_search
请求参数:
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"match_phrase": {
"providerSide": true
}
},
{
"match_phrase": {
"env.keyword": "production"
}
},
{
"range": {
"@timestamp": {
"format": "strict_date_optional_time",
"gte": "2024-05-01T00:00:00.000Z",
"lte": "2024-05-01T00:59:59.546Z"
}
}
}
]
}
},
"aggs": {
"interfaceId": {
"terms": {
"field": "interfaceId.keyword",
"order": {
"_key": "desc"
},
"size": 1
},
"aggs": {
"methodName": {
"terms": {
"field": "methodName.keyword",
"order": {
"_key": "desc"
},
"size": 1
},
"aggs": {
"max_count": {
"max_bucket": {
"buckets_path": "per_minute>_count"
}
},
"per_minute": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1m",
"time_zone": "Asia/Shanghai",
"min_doc_count": 1
}
}
}
}
}
}
}
} 返回数据删减
现在的请求基本上是可以拿到我们要的东西的,但是有个问题就是es会帮我们的请求数据汇聚里面的
"per_minute": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1m",
"time_zone": "Asia/Shanghai",
"min_doc_count": 1
}
} 计算的数据也返回给我们,每个接口,每分钟都有一条数据。这个数据我们是不要的,他只是为了计算:max_count的数据的。我们可以通过给请求参数增加过滤来屏蔽这个数据:
请求地址改成:
http://elasticsearch:9200/http-request-log-*/_search?filter_path=-aggregations.**.per_minute
拿到更多数据
相应的,架构搭好之后我们可以很方便的拿到更多需要的数据,比如平均请求数据,平均接口延迟(elapsedTime)等等:
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"match_phrase": {
"providerSide": true
}
},
{
"match_phrase": {
"env.keyword": "production"
}
},
{
"range": {
"@timestamp": {
"gte": "2024-05-01T00:00:00.000+08:00",
"lte": "2024-05-01T00:59:59.999+08:00"
}
}
}
]
}
},
"aggs": {
"app": {
"terms": {
"field": "appName.keyword",
"order": {
"_key": "desc"
},
"size": 500
},
"aggs": {
"average_elapsed_time": {
"avg": {
"field": "elapsedTime"
}
},
"interfaceId": {
"terms": {
"field": "interfaceId.keyword",
"order": {
"_key": "desc"
},
"size": 500
},
"aggs": {
"methodName": {
"terms": {
"field": "methodName.keyword",
"order": {
"_key": "desc"
},
"size": 200
},
"aggs": {
"average_elapsed_time": {
"avg": {
"field": "elapsedTime"
}
},
"latency_percentiles": {
"percentiles": {
"field": "elapsedTime",
"percents": [
50,
95,
99
]
}
},
"max_count_per_minute": {
"max_bucket": {
"buckets_path": "per_minute>_count"
}
},
"avg_count_per_minute": {
"avg_bucket": {
"buckets_path": "per_minute>_count"
}
},
"per_minute": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1m",
"time_zone": "Asia/Shanghai",
"min_doc_count": 1
}
}
}
}
}
}
}
}
}
}elasticsearch还是非常牛逼的,之前只是用到的一些毛皮
参考资料: